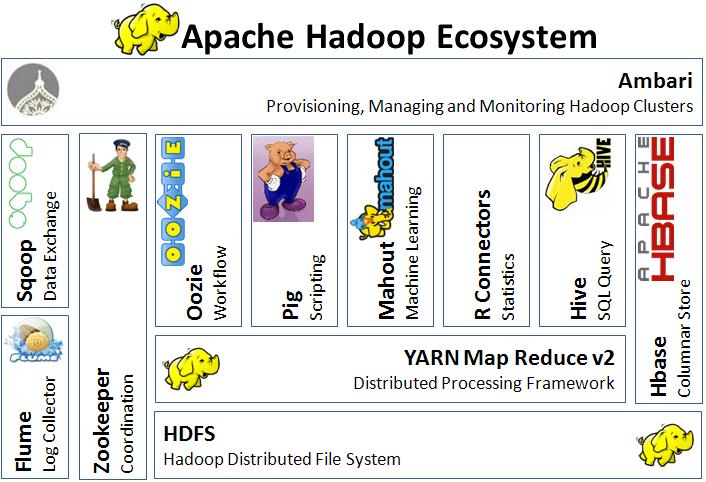
Before you can traverse through the Hadoop environment it is important to identify and learn about the key players. In this post I will provide an overview of the applications, tools and interfaces currently available in the Hadoop ecosystem. I will categorize each product by its functionality (Storage, Processing, Querying, External Integration & Coordination) and provide a description along with architecture, uses and resource likes. It is important to note that in a few months or years these products might become obsolete and replaced by another.
1. Storage
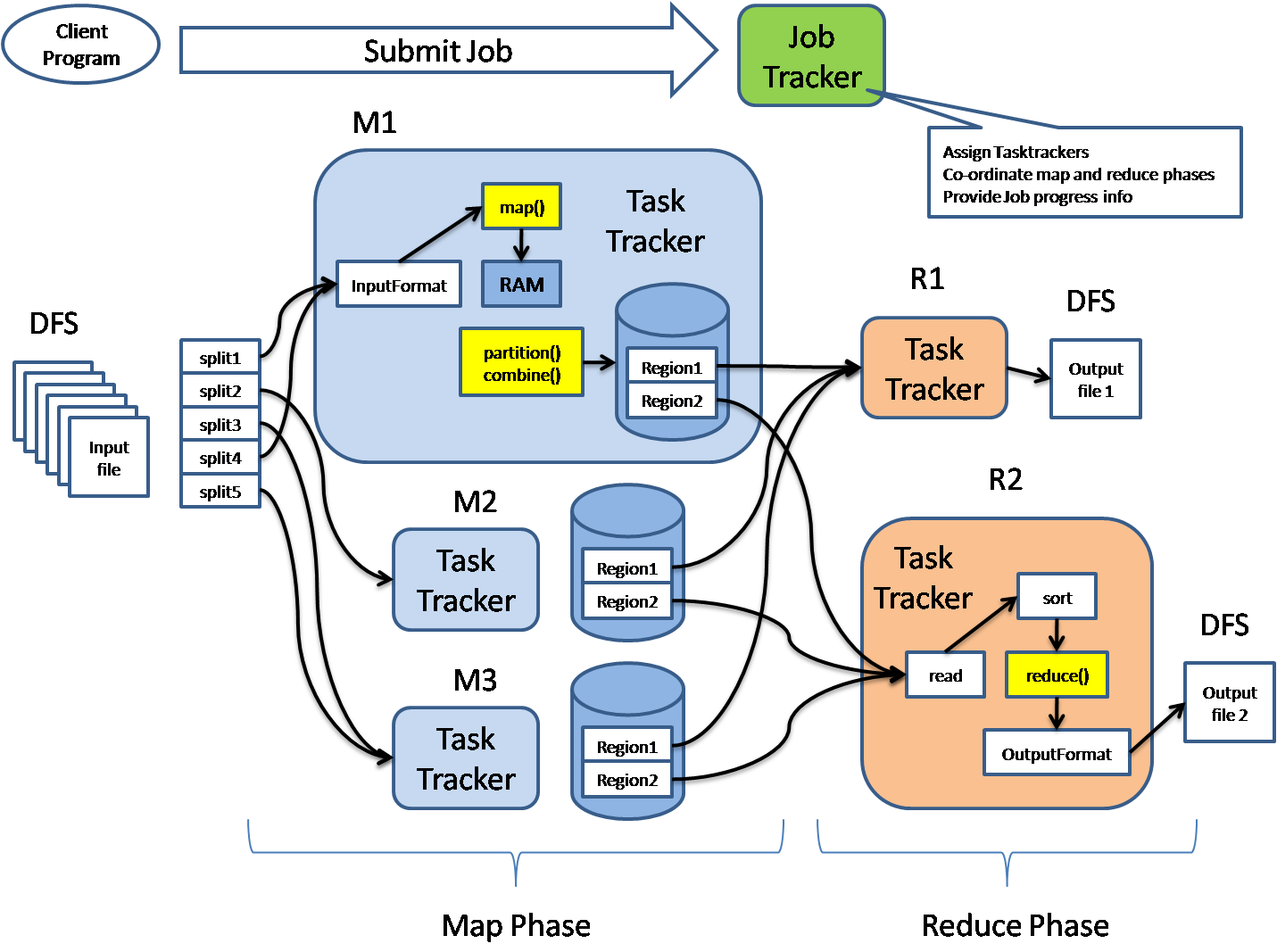
HDFS
The primary distributed file system used by Hadoop applications which runs on large clusters of commodity machines. HDFS clusters consist of a NameNode that manages the file system metadata and DataNodes that store the actual data.
Architecture:
HDFS Architecture
Uses:
-Storage of large imported files from applications outside of the Hadoop ecosystem
-Staging of imported files to be processed by Hadoop applications
Resource:
http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html
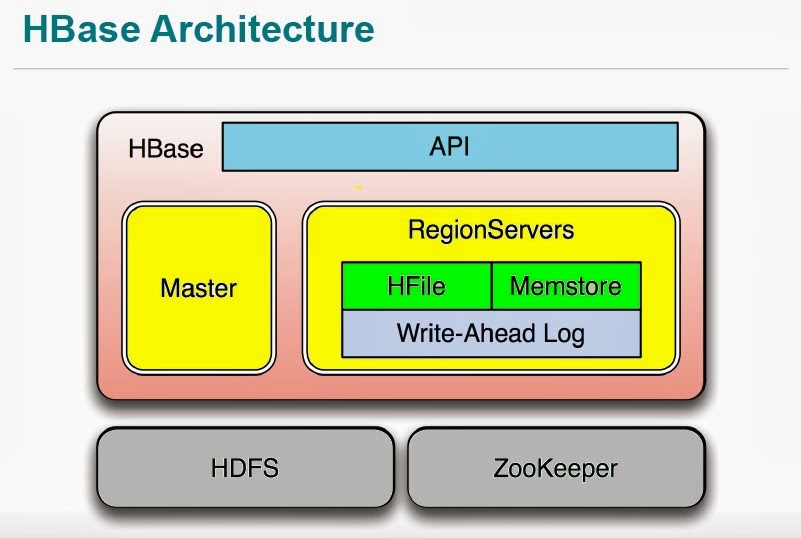
HBase
A distributed, column-oriented database. HBase uses HDFS for its underlying storage, and supports both batch-style computations using MapReduce and point queries (random reads).
Architecture:
HBase Architecture
Uses:
-Storage of large data volumes (billions of rows) atop clusters of commodity hardware
-Bulk storage of logs, documents, real-time activity feeds and raw imported data
-Consistent performance of reads/writes to data used by Hadoop applications
-Data Store than can be aggregated or processed using MapReduce functionality
-Data platform for Analytics and Machine Learning
Resource:
http://hbase.apache.org/book/architecture.html
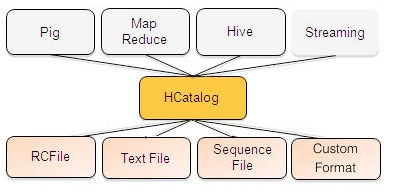
HCatalog
A table and storage management layer for Hadoop that enables Hadoop applications (Pig, MapReduce, and Hive) to read and write data to a tabular form as opposed to files. It also provides REST APIs so that external systems can access these tables’ metadata.
Architecture:
HCatalog Architecture
Uses:
-Centralized location of storage for data used by Hadoop applications
-Reusable data store for sequenced and iterated Hadoop processes (ex: ETL)
-Storage of data in a relational abstraction
Resource:
https://cwiki.apache.org/confluence/display/Hive/HCatalog
The primary distributed file system used by Hadoop applications which runs on large clusters of commodity machines. HDFS clusters consist of a NameNode that manages the file system metadata and DataNodes that store the actual data.
Architecture:
HDFS Architecture
Uses:
-Storage of large imported files from applications outside of the Hadoop ecosystem
-Staging of imported files to be processed by Hadoop applications
Resource:
http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html
HBase
A distributed, column-oriented database. HBase uses HDFS for its underlying storage, and supports both batch-style computations using MapReduce and point queries (random reads).
Architecture:
HBase Architecture
Uses:
-Storage of large data volumes (billions of rows) atop clusters of commodity hardware
-Bulk storage of logs, documents, real-time activity feeds and raw imported data
-Consistent performance of reads/writes to data used by Hadoop applications
-Data Store than can be aggregated or processed using MapReduce functionality
-Data platform for Analytics and Machine Learning
Resource:
http://hbase.apache.org/book/architecture.html
HCatalog
A table and storage management layer for Hadoop that enables Hadoop applications (Pig, MapReduce, and Hive) to read and write data to a tabular form as opposed to files. It also provides REST APIs so that external systems can access these tables’ metadata.
Architecture:
HCatalog Architecture
Uses:
-Centralized location of storage for data used by Hadoop applications
-Reusable data store for sequenced and iterated Hadoop processes (ex: ETL)
-Storage of data in a relational abstraction
Resource:
https://cwiki.apache.org/confluence/display/Hive/HCatalog
2. Processing
MapReduce
A distributed data processing model and execution environment that runs on large clusters of commodity machines. It uses the MapReduce algorithm which breaks down all operations into Map or Reduce functions.
Architecture:
MapReduce Architecture
Uses:
-Aggregation (Counting, Sorting, Filtering, Stitching) on large and desperate data sets
-Scalable parallelism of Map or Reduce tasks
-Distributed task execution
-Machine learning
Resource:
http://hadoop.apache.org/docs/r1.0.4/mapred_tutorial.html#Purpose
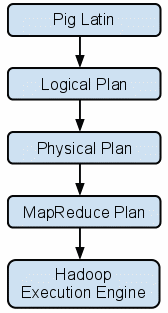
Pig
A scripting SQL based language and execution environment for creating complex MapReduce transformations. Functions are written in Pig Latin (the language) and translated into executable MapReduce jobs. Pig also allows the user to create extended functions (UDFs) using Java.
Architecture:
Pig Architecture
Uses:
-Scripting environment to execute ETL tasks/procedures on raw data in HDFS
-SQL based language for creating and running complex MapReduce functions
-Data processing, stitching, schematizing on large and desperate data sets
Resource:
http://pig.apache.org/docs/r0.12.1/index.html
A distributed data processing model and execution environment that runs on large clusters of commodity machines. It uses the MapReduce algorithm which breaks down all operations into Map or Reduce functions.
Architecture:
MapReduce Architecture
Uses:
-Aggregation (Counting, Sorting, Filtering, Stitching) on large and desperate data sets
-Scalable parallelism of Map or Reduce tasks
-Distributed task execution
-Machine learning
Resource:
http://hadoop.apache.org/docs/r1.0.4/mapred_tutorial.html#Purpose
Pig
A scripting SQL based language and execution environment for creating complex MapReduce transformations. Functions are written in Pig Latin (the language) and translated into executable MapReduce jobs. Pig also allows the user to create extended functions (UDFs) using Java.
Architecture:
Pig Architecture
Uses:
-Scripting environment to execute ETL tasks/procedures on raw data in HDFS
-SQL based language for creating and running complex MapReduce functions
-Data processing, stitching, schematizing on large and desperate data sets
Resource:
http://pig.apache.org/docs/r0.12.1/index.html
3. Querying
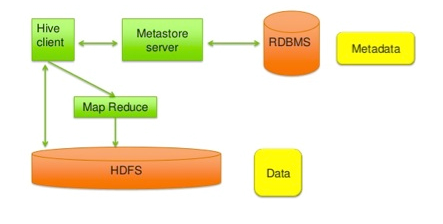
HIVE
A distributed data warehouse built on top of HDFS to manage and organize large amounts of data. Hive provides a query language based on SQL semantics (HiveQL) which is translated by the runtime engine to MapReduce jobs for querying the data.
Architecture:
Hive Architecture
Uses:
-Schematized data store for housing large amounts of raw data
-SQL-like Environment to execute analysis and querying tasks on raw data in HDFS
-Integration with outside RDBMS applications
Resource:
https://cwiki.apache.org/confluence/display/Hive/Home#Home-ApacheHive
A distributed data warehouse built on top of HDFS to manage and organize large amounts of data. Hive provides a query language based on SQL semantics (HiveQL) which is translated by the runtime engine to MapReduce jobs for querying the data.
Architecture:
Hive Architecture
Uses:
-Schematized data store for housing large amounts of raw data
-SQL-like Environment to execute analysis and querying tasks on raw data in HDFS
-Integration with outside RDBMS applications
Resource:
https://cwiki.apache.org/confluence/display/Hive/Home#Home-ApacheHive
4. External integration
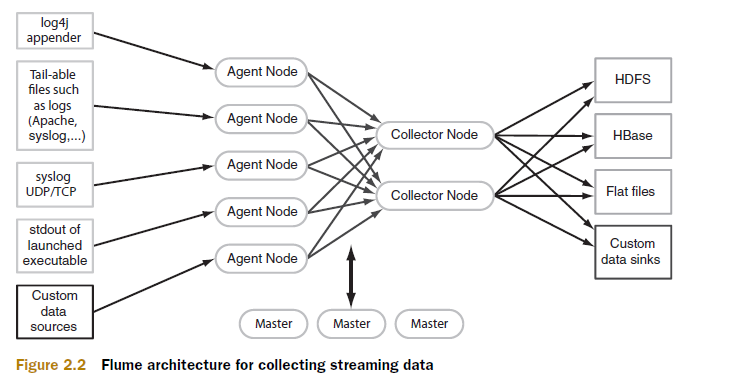
Flume
A distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data into HDFS. Flume's transports large quantities of event data using a steaming data flow architecture that is fault tolerant and failover recovery ready.
Architecture:
Flume Architecture
Uses:
-Transportation of large amounts of event data (network traffic, logs, email messages)
-Stream data from multiple sources into HDFS
-Guaranteed and reliable real-time data streaming to Hadoop applications
Resource:
http://flume.apache.org/FlumeUserGuide.html
A distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data into HDFS. Flume's transports large quantities of event data using a steaming data flow architecture that is fault tolerant and failover recovery ready.
Architecture:
Flume Architecture
Uses:
-Transportation of large amounts of event data (network traffic, logs, email messages)
-Stream data from multiple sources into HDFS
-Guaranteed and reliable real-time data streaming to Hadoop applications
Resource:
http://flume.apache.org/FlumeUserGuide.html
 RSS Feed
RSS Feed

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}