One of the 3 Vs (Velocity, Variety, Volume) of Big Data is Variety. 80-90% of all potentially usable business information may originate in unstructured form. This data comes from locations such as logs, texts, messages, usage, RFID scanners, monitoring devices. Traditionally these sources seemed to produce data in such large volumes and disparate formats (unstructured) which proved to be conducive to RDBMS systems. As a result they were cast aside and stored to be used someday. Today, mainstream NoSQL technologies have now enabled us to tap into these different types of data and integrate/utilize their data to provide a more holistic understanding of a business, product or customer. Despite the usability of unstructured and semi-structured data, the need for structured data still remains for systems that depend upon transactional and relational data.
In order to understand the different types of data as well as their similarities/differences we use the perspective of schema. The presence of schema allows us to classify the usability and operability of data. Data without the presence of schema provides very limited use. Data with static and standardized schema provides unlimited use. Listed below is a breakdown of unstructured, semi-structured and structured types of data with respect to schema.
In order to understand the different types of data as well as their similarities/differences we use the perspective of schema. The presence of schema allows us to classify the usability and operability of data. Data without the presence of schema provides very limited use. Data with static and standardized schema provides unlimited use. Listed below is a breakdown of unstructured, semi-structured and structured types of data with respect to schema.
1. Unstructured = NO SCHEMA
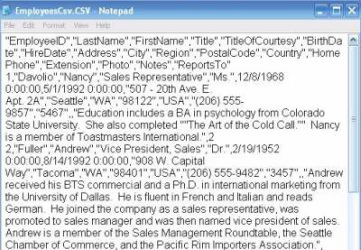
Unstructured data is a classification for data that can be of any type. This data does not follow any formats, sequences, patterns . Unstructured data is raw outputs from sources and into a container (file) which can be stored. Unschematized is a good way to classify this data because there are no rules that govern the data which allow applications or systems to make sense of the data. The lack of a schema also prevents this data from being processed, stored or aggregated by traditional RDBMS databases or applications. Unstructured data represents raw information in the world of technology and often needs to be schematized in order to be used.
Sources:
-Database Log Programs
-Application Log Programs
-Database Extracts
-Application Data Extracts
-Text/Messages
-RFID scanners
-Mobile Devices
Types:
-CSV Files
-Flat Files
-Log Files
-Scanner Log Files
-Pictures
-Videos
-Sounds
Example:
Sources:
-Database Log Programs
-Application Log Programs
-Database Extracts
-Application Data Extracts
-Text/Messages
-RFID scanners
-Mobile Devices
Types:
-CSV Files
-Flat Files
-Log Files
-Scanner Log Files
-Pictures
-Videos
-Sounds
Example:
2.Semi-Structured = VARIABLE SCHEMA
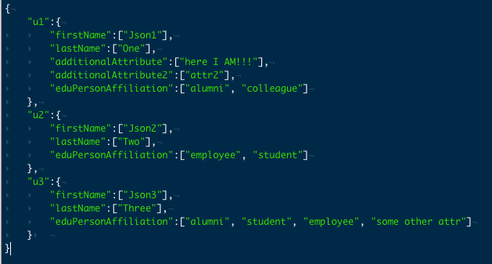
Semi-Structured data is a classification for data that is discernable yet heterogeneous and not static. This data does formats, sequences, patterns yet they are all subject to change intermittently within the same dataset . Semi-Structured data is extracts from sources that store information in hierarchies and elements. Variable Schema is a good way to classify this data because there are general rules that govern the data which allow applications or systems to make sense of the data, however, no one set of rules can apply to all of the data. There can be cases were there are multiple sets of rules within one dataset. The lack of a static schema also prevents this data from being processed, stored or aggregated by traditional RDBMS databases or applications but it can be utilized using NoSQL databases and applications. Semi-Structured data represents heterogeneous and dynamic (constantly changing) information in the world of technology. This is the new norm of data and no longer needs to be schematized with a static structure to be used.
Sources:
-Document Store Databases
-Graph Databases
-Web Data
-Social Network Data
-Demographic/Socio-Economic Data
-Web Crawler Extracts
Types:
-JSON
-XML
Example:
Sources:
-Document Store Databases
-Graph Databases
-Web Data
-Social Network Data
-Demographic/Socio-Economic Data
-Web Crawler Extracts
Types:
-JSON
-XML
Example:
3. Structured = STATIC SCHEMA
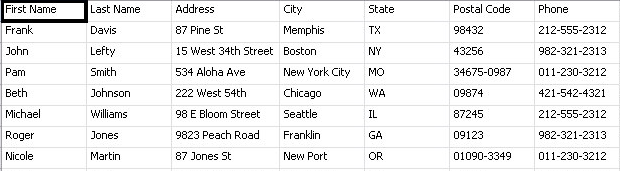
Structured data is a classification for data that is discernable, storable and usable by all databases and applications. This data follow established and accepted formats, sequences, patterns such as ASCII (American Standard Code for Information Interchange) or Primitive Data Types . Structured data is raw data that has been schematized, normalized and stored in relational or transactional databases. Schematized is a good way to classify this data because there are clearly defined and enforced rules that govern the data which allow applications or systems to use the data. The schema also allows this data to be processed, stored or aggregated by traditional RDBMS databases or applications. Structured data represents defined, normalized and usable information in the world of technology. This is the old norm of data and only applies to a small portion of the data generated today. Only transactional and relational applications remain as the major users for this type of data.
Sources:
-RDBMS Databases
-RDBMS Table Extracts
-Transactional System Data Extract
-CRM System Extract
Types:
-Structure Data Files (SDF)
-Excel Files
Example:
Sources:
-RDBMS Databases
-RDBMS Table Extracts
-Transactional System Data Extract
-CRM System Extract
Types:
-Structure Data Files (SDF)
-Excel Files
Example:
 RSS Feed
RSS Feed
