Hardware architecture
With the diversity of use for Hadoop it can be difficult for organizations to solidify on what commodity hardware can be used to sustain a Hadoop cluster. This post is designed to provide an overview of the hardware architecture as well as examples of hardware that can be/is used. It is important to note that every instance and use is different, thus, the hardware examples specified in this post should be taken as just examples.
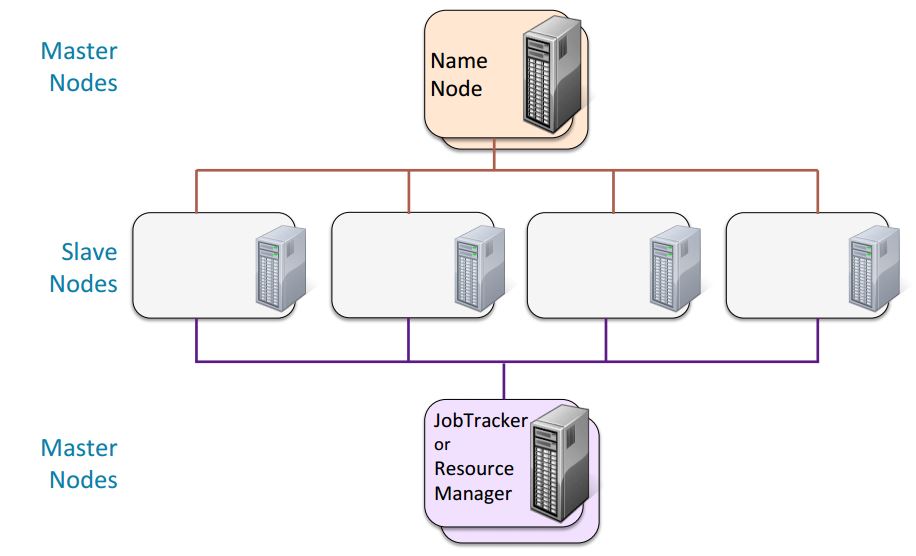
Master Nodes
Slave Nodes make up the vast majority of machines and do all the dirty work of storing the data and running the computations. Each slave runs both a Data Node and Task Tracker daemon that communicate with and receive instructions from their master nodes.
Listed below is an example for a middle grade hardware used for Slave Nodes.
Listed below is an example for a middle grade hardware used for Slave Nodes.
slave nodes
Processors: Mid-grade processors (ex: 2 x 6-core 3 GHz)
Memory: 48-96GB RAM
Network: 1Gb Ethernet
Drives: 6 x 2TB drives per node (Non-RAID)
Memory: 48-96GB RAM
Network: 1Gb Ethernet
Drives: 6 x 2TB drives per node (Non-RAID)
The Master nodes oversee the two key functional pieces that make up Hadoop: storing lots of data (HDFS), and running parallel computations on all that data (Map Reduce). The Name Node oversees and coordinates the data storage function (HDFS), while the Job Tracker oversees and coordinates the parallel processing of data using Map Reduce.
Listed below is an example for a middle grade hardware used for Master Nodes.
Listed below is an example for a middle grade hardware used for Master Nodes.
Processors: Mid-grade processors (ex: 2 x 6-core 3 GHz)
Memory: 64-128GB RAM
Network: 10Gb Ethernet
Drives: 12 x 3TB drives per node (RAID)
Memory: 64-128GB RAM
Network: 10Gb Ethernet
Drives: 12 x 3TB drives per node (RAID)
 RSS Feed
RSS Feed
