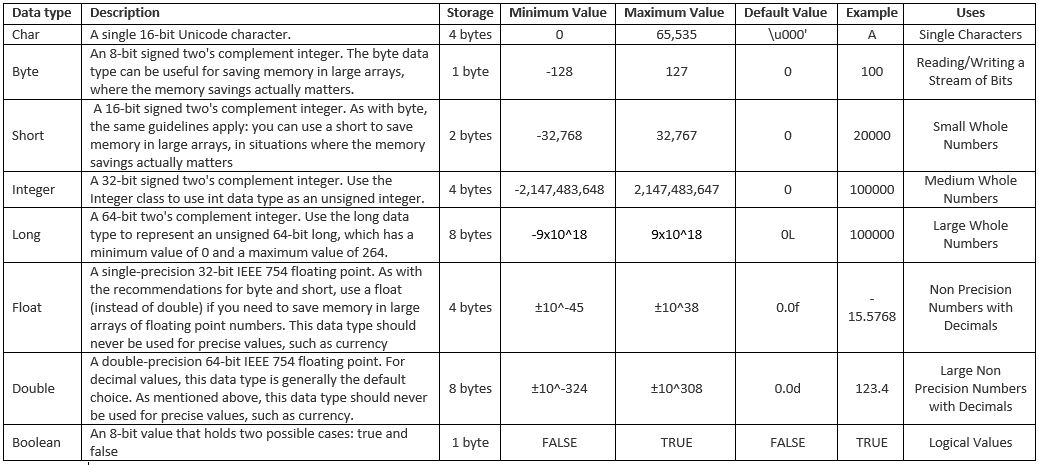
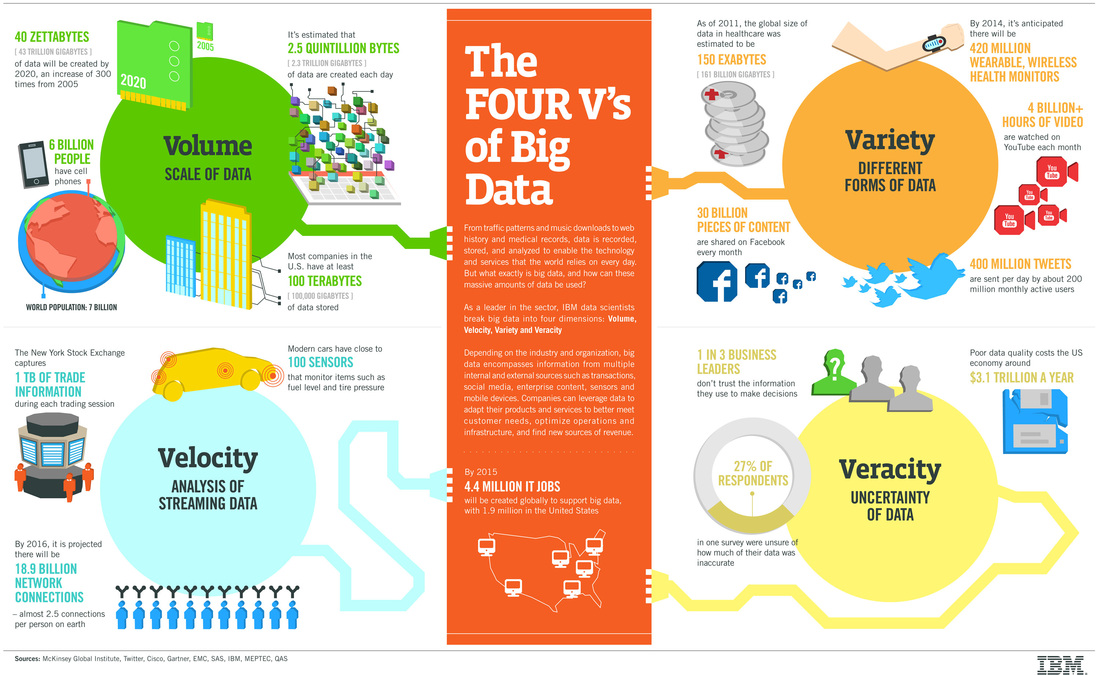
Many of the big data tools and technologies are underwritten in languages like Java or C++. These languages use a set of primitive data types to store information. Given the velocity, variety and volume of data expected in this new Big Data Age, it is crucial to understand the limitations and uses for these data types.
I am posting a quick overview of the basic primitive data types. Listed below is a table that will provide information on the usage, storage size and default values. For most of you this may be general knowledge but it never hurts to have a quick reference guide or refresher.
I am posting a quick overview of the basic primitive data types. Listed below is a table that will provide information on the usage, storage size and default values. For most of you this may be general knowledge but it never hurts to have a quick reference guide or refresher.
 RSS Feed
RSS Feed
