Overview
Data Quality is an integral part to any system that deals with data. The quality, reliability and usability of data is paramount to its value. Unfortunately, data quality issues run all too rampant within the data infrastructure of an organization. To be able to correlate data quality issues to business impacts, one must be able to classify data quality exceptions and assess the impact. As such, one of the most valuable exercises when implementing a data quality solution is to profile the data across the four common dimensions of data quality
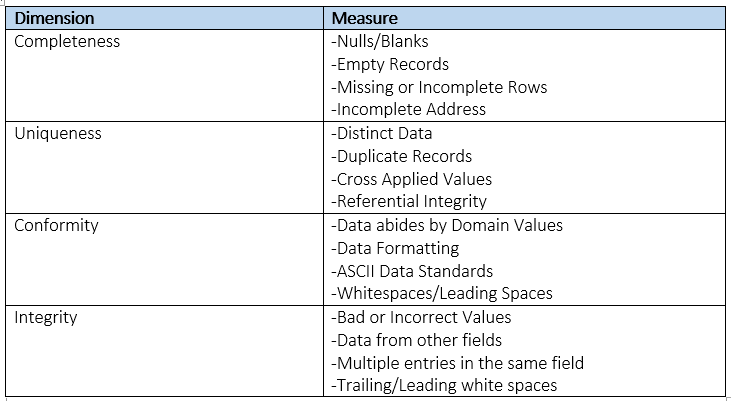
Dimensions
1. Completeness
Determination of what data is missing and incomplete. Checks in this areas identify what data values are missing or are in an unusable state. The incompleteness of data can be a result of omitted records, accidental deletion or non-required fields. Completeness can be critical to business processes and the accuracy of information.
Determination of what data is missing and incomplete. Checks in this areas identify what data values are missing or are in an unusable state. The incompleteness of data can be a result of omitted records, accidental deletion or non-required fields. Completeness can be critical to business processes and the accuracy of information.
2. Uniqueness
Determination if data is deduplicated and unique. Checks in this areas identify duplicated data. The uniqueness of data can be a result of merged systems, data re-entry and multiple source systems. Uniqueness is a key functionality of Master Data Management and data sharing across an organization
Determination if data is deduplicated and unique. Checks in this areas identify duplicated data. The uniqueness of data can be a result of merged systems, data re-entry and multiple source systems. Uniqueness is a key functionality of Master Data Management and data sharing across an organization
3. Conformity
Determination if data abides by the standards of the organization and industry regulations. Checks in this areas identify what data values do not conform to integrity, column or row formatting/standards. The non-conformity of data can be a result of non enforced data standards, imported data from unstructured sources or lack of data integrity constraints. Conformity can be vital to the usability and sharing of data across platforms.
Determination if data abides by the standards of the organization and industry regulations. Checks in this areas identify what data values do not conform to integrity, column or row formatting/standards. The non-conformity of data can be a result of non enforced data standards, imported data from unstructured sources or lack of data integrity constraints. Conformity can be vital to the usability and sharing of data across platforms.
4. Integrity
Determination if data is corrupted or decayed. Checks in this areas identify what data values are include erroneous, incorrect and junk information. Bad data can be a result of non enforced data standards, dummy data left in the system and lazy data entry. Integrity is very important to the reliability, accuracy and usability of data in key business processes.
Determination if data is corrupted or decayed. Checks in this areas identify what data values are include erroneous, incorrect and junk information. Bad data can be a result of non enforced data standards, dummy data left in the system and lazy data entry. Integrity is very important to the reliability, accuracy and usability of data in key business processes.
Measures
 RSS Feed
RSS Feed
