Overview
In today's digital world the volume, variety and velocity of data is growing at a exponential rate. Data collection, analysis and processing has reached a point that it cannot be effectively managed using conventional relational database management systems (RDBMS). To handle this problem an alternate set of non-relational, horizontally scalable and distributed data stores have emerged, known as NoSQL databases.
NoSQL refers to a group of non-relational database management system (DBMS) that are not dependent on tables and do not use SQL for data manipulation. NoSQL databases are typically distributed, non-relational databases designed for large-scale data storage and massively-parallel data processing. They use non-SQL languages and mechanisms to interact with data and support traditional activities such as exploratory analytics, data transformation and on-line transactional processing (OLTP).
NoSQL databases can be classified into four categories based on the velocity of data, variety of data and operations.
1. Key-Value Stores
2. Column Stores
3. Document Stores
4. Graph Databases
NoSQL refers to a group of non-relational database management system (DBMS) that are not dependent on tables and do not use SQL for data manipulation. NoSQL databases are typically distributed, non-relational databases designed for large-scale data storage and massively-parallel data processing. They use non-SQL languages and mechanisms to interact with data and support traditional activities such as exploratory analytics, data transformation and on-line transactional processing (OLTP).
NoSQL databases can be classified into four categories based on the velocity of data, variety of data and operations.
1. Key-Value Stores
2. Column Stores
3. Document Stores
4. Graph Databases
Types
Key-Value STORE
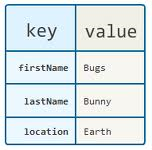
Key-value stores are the most basic type of NoSQL database. Every item in the database is stored as an attribute name, or key, together with its value similar to a dictionary or map table. The content of the value is not readable or recognized by the system, data can only be queried by the key. This model can be useful for representing polymorphic and unstructured data, as the database does not enforce a set schema across key-value pairs.
Data Model:
Data is stored as values paired with an alpha-numeric identifier known as key. Keys represent pointers to the location and order of the values they are mapped to. Values represent a single piece of information or can be multiple pieces of information together in a collection like an Array or List. Values can even represent pointers to the location and order of other values. Keys and Values are both stored in standalone tables.
Key-Value Store Data Model
Types:
-Eventually Consistency
-Immediately Consistency
-Atomic Consistency
Storage:
-String
-Lists
-Sets
-Sorted Sets
-Hashes
-Arrays
Use Cases:
-Storage of online session information from web applications
-Storing transactional information for online shopping and e-commerce
-Catalog for web application data like product details, advertisements and users
Advantages:
-Fast retrieval of values
-Highly available
-Easy to scale and distribute
Disadvantages:
-Difficult to query or update parts of values
-Not meant for connected data that has relationships (relational data)
Examples:
-Redis
-MemcacheDB
-Dynamo
Data Model:
Data is stored as values paired with an alpha-numeric identifier known as key. Keys represent pointers to the location and order of the values they are mapped to. Values represent a single piece of information or can be multiple pieces of information together in a collection like an Array or List. Values can even represent pointers to the location and order of other values. Keys and Values are both stored in standalone tables.
Key-Value Store Data Model
Types:
-Eventually Consistency
-Immediately Consistency
-Atomic Consistency
Storage:
-String
-Lists
-Sets
-Sorted Sets
-Hashes
-Arrays
Use Cases:
-Storage of online session information from web applications
-Storing transactional information for online shopping and e-commerce
-Catalog for web application data like product details, advertisements and users
Advantages:
-Fast retrieval of values
-Highly available
-Easy to scale and distribute
Disadvantages:
-Difficult to query or update parts of values
-Not meant for connected data that has relationships (relational data)
Examples:
-Redis
-MemcacheDB
-Dynamo
Column Store
Column stores, or wide-column stores are one of newer types of NoSQL databases. They use multi-dimensional sorted map tables to store data. Each item is stored as a record inn a column based on what the subject or type of data. Columns are grouped together in column families to create relationships or exist in isolation. This model can be useful for quickly writing large amounts of structured and unstructured data.
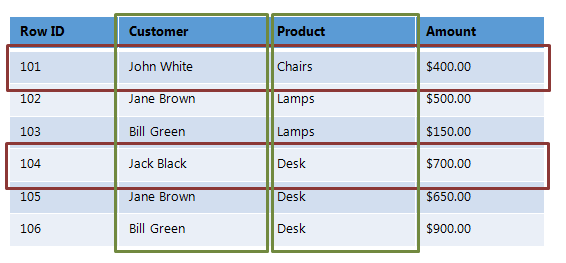
Data Model:
Data is stored as rows in single column tables known as columns. Rows represent a single piece of information or can be multiple pieces of information together in a collection like an Array or List. Columns represent a single column table of rows that contain information pertaining to one subject or type. Columns can be grouped together for access in column families. Data is queried and retrieved by the primary key assigned to each column or column family. Column stores use a similar data model to Key-Value pairs but allow for multiple columns (values) to be associated to one set of keys. This makes parallel querying across columns possible and fast.
Column Store Data Model
Types:
-Column-Family Store
-Column Store
Storage:
-Usage data
-Sensor and Telemetry data
-Time series events
-Logs
Use Cases:
-Storing real time environmental telemetry data from sensors, monitoring systems and scanners
-Storing real time stock market data for risk analysis, financial systems and trading
-Reporting on web site metrics like click-through rate, page views and page interactions
Advantages:
-Large scale batch data processing (sorting, parsing, converting and aggregating)
-Fast data writes
-Distributed data storage of versioned data
-Partitioned and replicated data
Disadvantages:
-Exponentially increasing disk seek time as multiple columns are added to column families
-Slow querying for data spread out across large column families
-Reconstruction costs for stitching together data queried across columns
Examples:
-Cassandra
-HBase
-Google BigTable
Data Model:
Data is stored as rows in single column tables known as columns. Rows represent a single piece of information or can be multiple pieces of information together in a collection like an Array or List. Columns represent a single column table of rows that contain information pertaining to one subject or type. Columns can be grouped together for access in column families. Data is queried and retrieved by the primary key assigned to each column or column family. Column stores use a similar data model to Key-Value pairs but allow for multiple columns (values) to be associated to one set of keys. This makes parallel querying across columns possible and fast.
Column Store Data Model
Types:
-Column-Family Store
-Column Store
Storage:
-Usage data
-Sensor and Telemetry data
-Time series events
-Logs
Use Cases:
-Storing real time environmental telemetry data from sensors, monitoring systems and scanners
-Storing real time stock market data for risk analysis, financial systems and trading
-Reporting on web site metrics like click-through rate, page views and page interactions
Advantages:
-Large scale batch data processing (sorting, parsing, converting and aggregating)
-Fast data writes
-Distributed data storage of versioned data
-Partitioned and replicated data
Disadvantages:
-Exponentially increasing disk seek time as multiple columns are added to column families
-Slow querying for data spread out across large column families
-Reconstruction costs for stitching together data queried across columns
Examples:
-Cassandra
-HBase
-Google BigTable
Document Store
Document stores are one of the most popular types of NoSQL databases. They use a structure like JSON (JavaScript Object Notation) to store data as documents. Each record and its associated data is stored together as a single document. Documents contain one or more fields, where each field contains a typed value, such as a string, date, binary or array. This model simplifies data access and reduces or even eliminates the need for joins and complex transactions
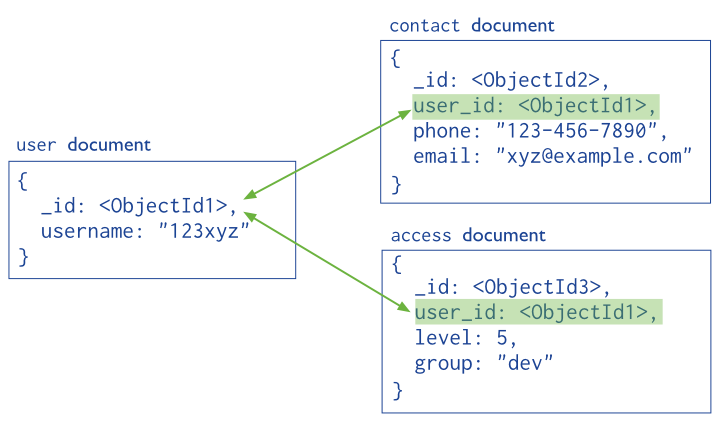
Data Model:
Data is stored as JSON structures known as documents paired with an alpha-numeric identifier known as a key. A document represent a collection of information or data file in object notation, represented with one or more fields, where each field contains a value. Each document can contain different fields because there is no enforced schema across documents. Keys represent pointers to the location and order of the documents they are mapped to. Document stores use a similar model to Key-Value pairs but allow unrelated whole documents and large pieces of information to be stored instead of single values.
Document Store Data Model
Types:
-Eventually Consistency
-Immediately Consistency
-Atomic Consistency
Storage:
-Text Documents
-Email messages
-XML Documents
-JSON Files
-Metadata
Use Cases:
-Storage of online and social media content like discussion threads, comments and likes
-Storing customer profile information for online gamers, social media, biometrics, identity/access management and CRM
-Storing repository information for customers, products, inventory and supply chain
-Storage of usage data like click-streams, logs, genomics
Advantages:
-Storing and managing large collections of documents
-Storing mixtures of semi-structured, unstructured and structured data
-Fast data writes
-Easily partition and shard data
Disadvantages:
-Querying data retrieves the entire contents of the document
-Un-enforced schema allows for relaxed constraints can allow unnecessarily large files of data to be written to the database without warning
Examples:
-MongoDB
-Couchbase
-BaseX
Data Model:
Data is stored as JSON structures known as documents paired with an alpha-numeric identifier known as a key. A document represent a collection of information or data file in object notation, represented with one or more fields, where each field contains a value. Each document can contain different fields because there is no enforced schema across documents. Keys represent pointers to the location and order of the documents they are mapped to. Document stores use a similar model to Key-Value pairs but allow unrelated whole documents and large pieces of information to be stored instead of single values.
Document Store Data Model
Types:
-Eventually Consistency
-Immediately Consistency
-Atomic Consistency
Storage:
-Text Documents
-Email messages
-XML Documents
-JSON Files
-Metadata
Use Cases:
-Storage of online and social media content like discussion threads, comments and likes
-Storing customer profile information for online gamers, social media, biometrics, identity/access management and CRM
-Storing repository information for customers, products, inventory and supply chain
-Storage of usage data like click-streams, logs, genomics
Advantages:
-Storing and managing large collections of documents
-Storing mixtures of semi-structured, unstructured and structured data
-Fast data writes
-Easily partition and shard data
Disadvantages:
-Querying data retrieves the entire contents of the document
-Un-enforced schema allows for relaxed constraints can allow unnecessarily large files of data to be written to the database without warning
Examples:
-MongoDB
-Couchbase
-BaseX
Graph
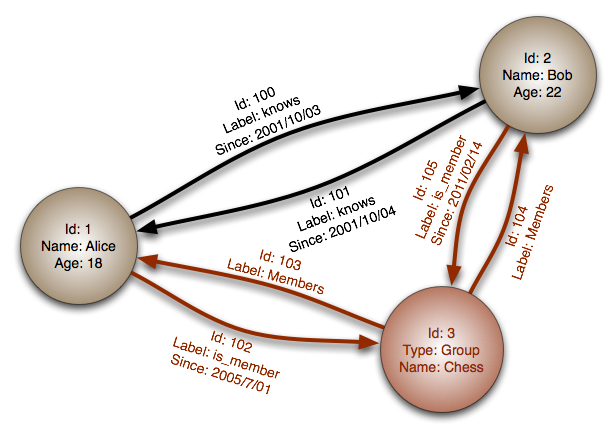
Graph databases use graph data structures with nodes, edges and properties to represent data. Data is modeled as a network of relationships between specific elements. This model makes it easier to conceptually organize and illustrate relationships between entities in an application.
Data Model:
Data is stored as node or relationship elements with properties. Nodes represent individual records similar to objects or entities. Relationships represent connections between nodes and act to organize nodes into structures similar to lists, trees and maps. Properties represent attributes and describing information about Nodes or Relationships.
Graph Database Data Model
Types:
-Eventually Consistency
- Immediately Consistency
- Atomic Consistency
Storage:
-Social media networks
-Insurance risk profiles
-Recommendation web
-Network and Data Center usage
-Intra-state supply chain
Use Cases:
-Storage of social network associations like friends, followings and groups
-Storing customer profile information for online gamers, social media, biometrics, identity/access management and CRM
-Storing repository information for customers, products, inventory and supply chain
-Storage of usage data like click-streams, logs, genomics
-Platform for complex data analysis and analytics
Advantages:
-Storing and managing large collections of interconnected and interrelated data
-Quickly traversing through the relationships between data
-Performing large scales queries without expensive joins
-Storing mixtures of semi-structured and structured data
Disadvantages:
-Not meant for transactional uses/applications (querying, writing, updating)
-Unable to horizontally partition or shard across multiple servers
-Not meant for disparate data that has missing or no relationships (non-relational data)
Examples:
-Neo4J
-OrientDB
-GraphDB
Data Model:
Data is stored as node or relationship elements with properties. Nodes represent individual records similar to objects or entities. Relationships represent connections between nodes and act to organize nodes into structures similar to lists, trees and maps. Properties represent attributes and describing information about Nodes or Relationships.
Graph Database Data Model
Types:
-Eventually Consistency
- Immediately Consistency
- Atomic Consistency
Storage:
-Social media networks
-Insurance risk profiles
-Recommendation web
-Network and Data Center usage
-Intra-state supply chain
Use Cases:
-Storage of social network associations like friends, followings and groups
-Storing customer profile information for online gamers, social media, biometrics, identity/access management and CRM
-Storing repository information for customers, products, inventory and supply chain
-Storage of usage data like click-streams, logs, genomics
-Platform for complex data analysis and analytics
Advantages:
-Storing and managing large collections of interconnected and interrelated data
-Quickly traversing through the relationships between data
-Performing large scales queries without expensive joins
-Storing mixtures of semi-structured and structured data
Disadvantages:
-Not meant for transactional uses/applications (querying, writing, updating)
-Unable to horizontally partition or shard across multiple servers
-Not meant for disparate data that has missing or no relationships (non-relational data)
Examples:
-Neo4J
-OrientDB
-GraphDB
Breakdown
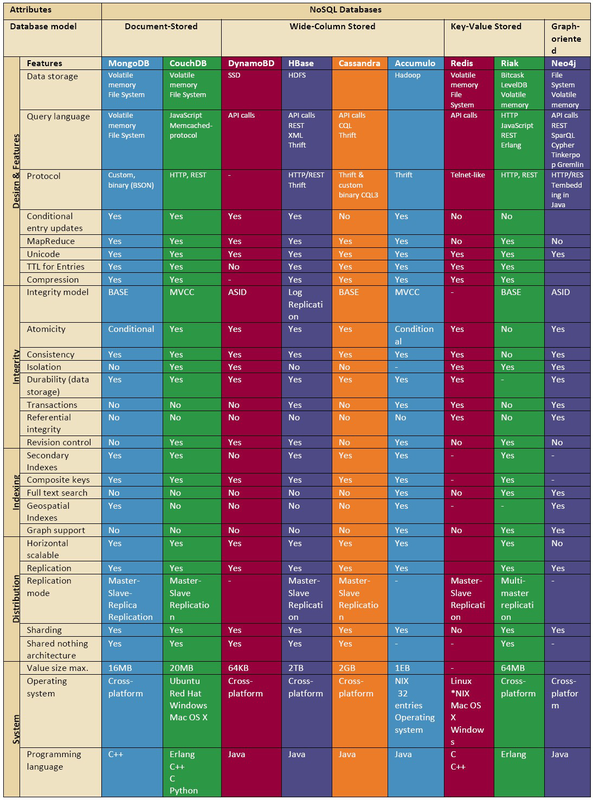
The table below is a detailed breakdown of the different NoSQL database types by key features that are used to measure the use, storage, extensibility, integration and performance of traditional databases. This table also adds technical details to many of the points that were discussed in the previous sections of this article.
 RSS Feed
RSS Feed

{kind=link}
{kind=link}
{kind=link}
{kind=link}