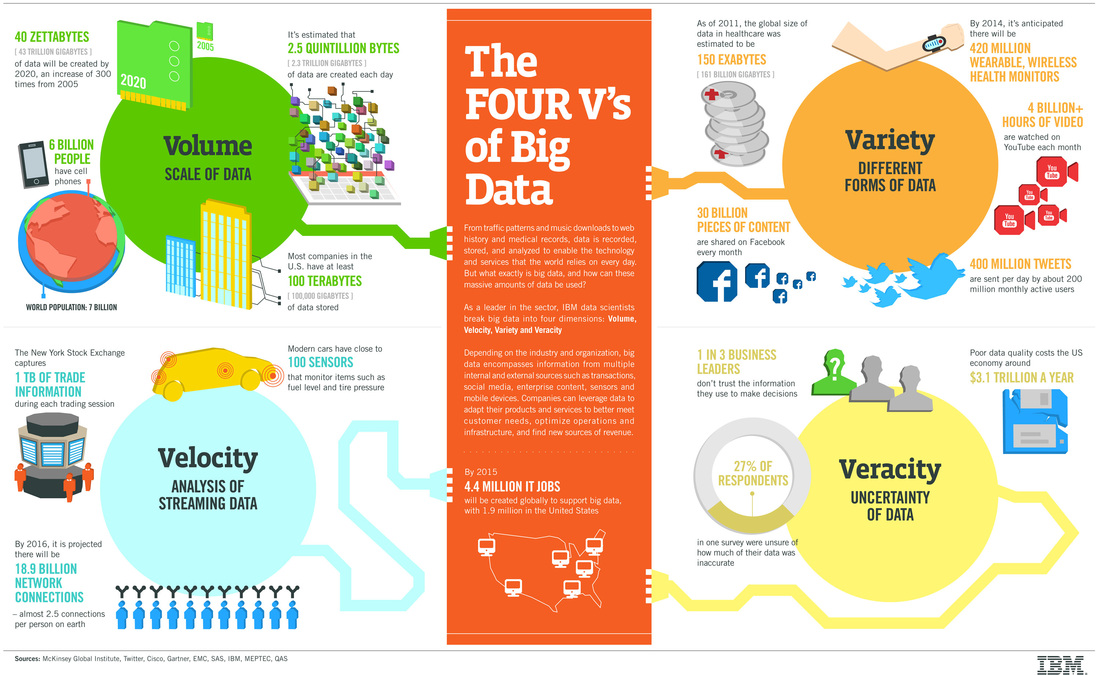
VARIETY
The variety of data is has expanded to be as vast as the number of sources that generate data. Data can be sourced from emails, audio players, video recorders, watches, personal devices, computers, health monitoring systems, satellites..etc. Each device that is recording data is recording and encoding it in a different format and pattern. Additionally, the data generated from these devices also can vary by granularity, timing, pattern and schema. The reward that this variety provides is flexibility to store different types of information without enforcing traditional relational constraints. Much of the data generated is based on object structures that very depending on an event, individual, transaction or location. Having data recorded in a flexible structure that can vary will provide biased and specific information.
Data collections for varied source and forms means that traditional relational databases and structures cannot be used to interpret and store this information. This poses a challenge because many organizations still cling to SQL and the relational world as they have for decades. NoSQL technologies are the solution to move us forward because of the flexible approach they bring to storing and reading data without imposing strict relational bindings. NoSQL systems such as Document Stores and Column Stores already provide a good replacement to OLTP/relational database technologies as well as read/write speeds that are much faster.
Data collections for varied source and forms means that traditional relational databases and structures cannot be used to interpret and store this information. This poses a challenge because many organizations still cling to SQL and the relational world as they have for decades. NoSQL technologies are the solution to move us forward because of the flexible approach they bring to storing and reading data without imposing strict relational bindings. NoSQL systems such as Document Stores and Column Stores already provide a good replacement to OLTP/relational database technologies as well as read/write speeds that are much faster.
VELOCITY
The velocity of data streaming is extremely fast paced. Technology has evolved to be integrated with all aspects of human life and as such data is generated across almost every interaction that humans make. Every millisecond, systems all around the world are generating data based on events and interactions. Devices like heart monitors, televisions, RFID scanners and traffic monitors generate data at the millisecond. Servers, weather devices, and social networks generate data at the second. As technology furthers, it would not be surprising to see devices that generated data even at the nanosecond. The reward that this data velocity provides is information in real time that can be harnessed to make near real time decisions or actions. Most of the traditional insights we have are based on aggregations of actuals over days and months. Having data at the grain of seconds or milliseconds will provide a more detailed and vivid information.
Organizations are often overwhelmed in embracing the amount of information that is generated and available for them. Managing the amount of data that is generated on a daily basis is becoming a serious challenge. With the speed in which data is generated, it demands equally, if not quicker, tools and technology to be able to extract, process and analyze the data. Traditional technologies of extracting, transforming and storing data can no longer handle the vast loads of data. This limitation has lead to the emergence of Big Data architectures and technologies. NoSQL, Distributed and Service Oriented Systems.
Organizations are often overwhelmed in embracing the amount of information that is generated and available for them. Managing the amount of data that is generated on a daily basis is becoming a serious challenge. With the speed in which data is generated, it demands equally, if not quicker, tools and technology to be able to extract, process and analyze the data. Traditional technologies of extracting, transforming and storing data can no longer handle the vast loads of data. This limitation has lead to the emergence of Big Data architectures and technologies. NoSQL, Distributed and Service Oriented Systems.
- NoSQL systems replace traditional OLTP/relational database technologies because they place less importance on ACID (Atomicity, Consistency, Isolation, Durability) principles and are able to read/write records at much faster speeds.
- Distributed and Load Balancing systems have now become a standard in all organizations to split and distribute the load of extracting, processing and analyzing data across a series of servers. This allows for large amounts of data to be processed in high speeds which eliminate bottle necks.
- Enterprise Service Bus (ESB) systems replace traditional integration frameworks written in custom code. These distributed and easily scalable systems allow for serialization across large workloads and applications to process large amounts of data to a variety of different applications and systems.
VOLUME
The volume of data generated today easily overshadows all of the data we have generated in the past. If we take all the data generated in the world between the beginning of time and 2008, the same amount of data will soon be generated every minute! Closely tied to Velocity, technology has evolved to be integrated with nearly all aspects of human life. As a result, billions of touchpoints generate Petabytes and Zettabytes of data. On social media and telecommunication sites alone, billions of messages, clicks and uploads take place everyday. The reward that this data volume provides is information for almost every touchpoint. We now have information for every interaction, perspective and alternate. Having this diverse data allows us to more effectively analyze, predict, test and ultimately prescribe to our customers.
Large collections of data coupled with the challenges of Variety (different formats) and Velocity (near real time generation) pose significant managing costs to organizations. Despite the pace of Moore's Law, the challenge to store large data sets can no longer be met with traditional databases or data stores. The strengths of distributed storage systems like SAN (Storage Area Network) as well as NoSQL data stores that are able effectively divide, compress and store large amounts of data with improved read/write performances.
Large collections of data coupled with the challenges of Variety (different formats) and Velocity (near real time generation) pose significant managing costs to organizations. Despite the pace of Moore's Law, the challenge to store large data sets can no longer be met with traditional databases or data stores. The strengths of distributed storage systems like SAN (Storage Area Network) as well as NoSQL data stores that are able effectively divide, compress and store large amounts of data with improved read/write performances.
Provided below is a great illustrative breakdown of the 3 Vs described above. In context, a fourth V, Veracity is often referenced. Veracity concerns the data quality risks and accuracy as data is generated at such a high and distributed frequency. In solving the challenge of the 3 Vs, organization put little emphasis or work into cleaning up the data and filtering on what is necessary and as a result the credibility and reliability of data have suffered.
 RSS Feed
RSS Feed
