Overview
In today's world, data exceeds the processing capacity of conventional database systems. The data we need/use is generated too quickly for traditional storage and processing systems. To gain value from this rapidly generated data we need to adopt an alternative way to harness it. The commonly adopted tools in the Hadoop/Big Data framework is MapReduce. It is a distributed data processing model and execution environment that runs on large clusters of commodity machines. Using the MapReduce algorithm it breaks down all operations into Map or Reduce functions. Using MapReduce a task of processing or storing data is distributed across a series of compute nodes. Each node process data in parallel allowing large and complex tasks to be completed in a fraction of the time.
Although, MapReduce exists as a solid solution to the "Volume" problem of Big Data, there is still a strong need for keeping data in a relational and SQL environment. Applications such as Data Warehouses, OLAP Cubes, OLTP systems and Business Intelligence platforms still drive big demand in enterprises all over the world. For these use cases, the traditional tools are not able to keep up with the volumes of data. For these applications, new Massively Parallel Processing (MPP) Appliances have been created. MPP Appliances provide parallel and distributed processing across an integrated set of servers, storage. They also are integrated with relational DBMS and Business Intelligence/Data Warehousing tools to provide a SQL interface and store data in a relational form. Their appliance package provides the ability to scale performance, storage and memory by adding servers. They also arrive at your data center pre-configured for your networking environment which means no need to manage disk systems, software configuration, hardware configuration and optimization.
Although there are many of these applications growing in demand and popularity, the market is currently dominated and lead by the following offerings:
Although, MapReduce exists as a solid solution to the "Volume" problem of Big Data, there is still a strong need for keeping data in a relational and SQL environment. Applications such as Data Warehouses, OLAP Cubes, OLTP systems and Business Intelligence platforms still drive big demand in enterprises all over the world. For these use cases, the traditional tools are not able to keep up with the volumes of data. For these applications, new Massively Parallel Processing (MPP) Appliances have been created. MPP Appliances provide parallel and distributed processing across an integrated set of servers, storage. They also are integrated with relational DBMS and Business Intelligence/Data Warehousing tools to provide a SQL interface and store data in a relational form. Their appliance package provides the ability to scale performance, storage and memory by adding servers. They also arrive at your data center pre-configured for your networking environment which means no need to manage disk systems, software configuration, hardware configuration and optimization.
Although there are many of these applications growing in demand and popularity, the market is currently dominated and lead by the following offerings:
- Microsoft Parallel Data Warehouse
- IBM Netezza
- Teradata Data Warehouse Appliance
- Oracle Exadata
- SAP HANA
- EMC Greenplum

SMP VS MPP
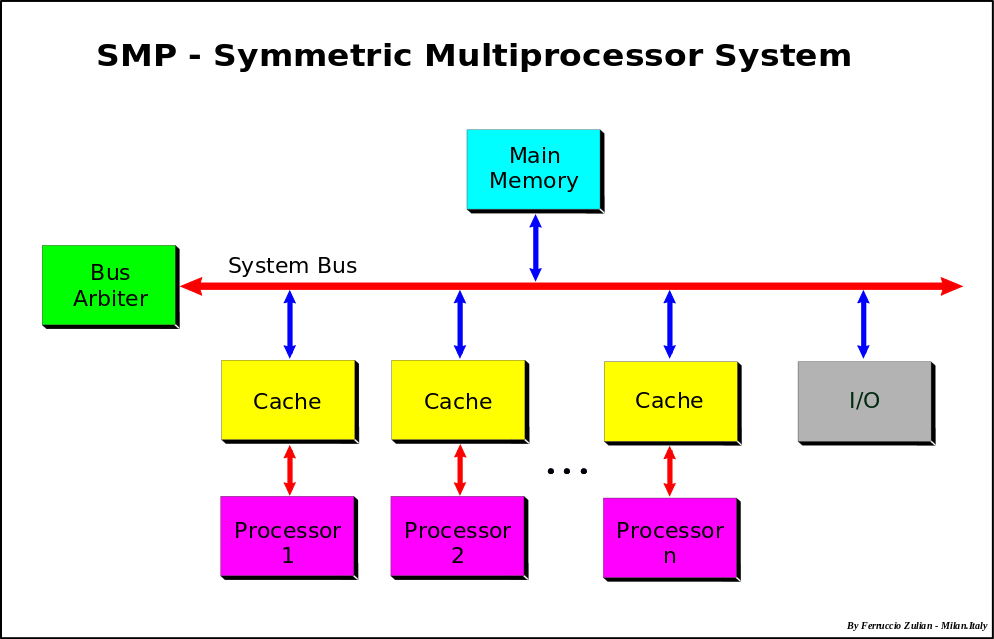
Symmetric Multi-Processing (SMP)
System architecture where all of the processors connect to shared resources (memory, I/O, and network) under a single operating system. Each processor has a private cache memory, access to the main memory. Processors are interconnected using buses, switches or chip networks.
SMP Architecture
Advantages:
- Relatively inexpensive single machine design (no racks needed)
- Symmetric distributed computing
- Efficiently/Quickly process small to medium data volumes
Disadvantages:
- Inefficient/Lengthy at processing large data volumes
- Scaling up or down requires a machine upgrade/downgrade
- Resource/Memory contention between processors
- External interrupts impact all processing
- Operating System limitation on scalability (OS can only support 64-100 multi-processors)
- Expensive (time and cost) to upgrade hardware
Massive Parallel Processing (MMP)
System architecture where processing is parallelly distributed processing across an integrated set of servers known as compute nodes. Each compute node contains its own set of processors, memory and bus. Each server also comes with its own operating system and DMBS allowing it to run as an independent processing unit . Compute nodes are interconnected using a control and management node which split, distribute and mange processing. Compute nodes can be added or remove by adding or removing servers to the rack.
MPP Architecture
Advantages:
- Relatively inexpensive hardware needed to scale (cost of new server is cheaper than buying a new machine)
- No resource contention across compute nodes
- Scaling up or down is easy and can be performed without taking down the system
- Ability to add failover and backup servers
- Efficiently/Quickly process large data volumes
- No limitation on the number of compute nodes that can be added
Disadvantages:
- Additional maintenance required (rack space, cooling, monitoring)
- Additional maintenance costs (power, cooling, hardware upgrades)
- Unused resources during small and medium data volumes
As mentioned earlier, traditional BI, Data Warehouse and DBMS tools are not able to keep up with the volumes of data. Moore's law is unable to keep up with velocity and volume of data growth. Shared resources and memory prevent scalability and distributed processing. These tools use a Symmetric Multi-Processing (SMP) architecture.
In order to accommodate for the hardware lag (disparity between Moor's Law and data growth), integration/coupling of hardware needs to be utilized. Massively Parallel Processing (MPP) architecture allows for the combination of hardware resources to be pooled to create a more powerful system that is able to meet the demands of processing and storing Big Data while still providing usability of tools using the SMP architecture.
System architecture where all of the processors connect to shared resources (memory, I/O, and network) under a single operating system. Each processor has a private cache memory, access to the main memory. Processors are interconnected using buses, switches or chip networks.
SMP Architecture
Advantages:
- Relatively inexpensive single machine design (no racks needed)
- Symmetric distributed computing
- Efficiently/Quickly process small to medium data volumes
Disadvantages:
- Inefficient/Lengthy at processing large data volumes
- Scaling up or down requires a machine upgrade/downgrade
- Resource/Memory contention between processors
- External interrupts impact all processing
- Operating System limitation on scalability (OS can only support 64-100 multi-processors)
- Expensive (time and cost) to upgrade hardware
Massive Parallel Processing (MMP)
System architecture where processing is parallelly distributed processing across an integrated set of servers known as compute nodes. Each compute node contains its own set of processors, memory and bus. Each server also comes with its own operating system and DMBS allowing it to run as an independent processing unit . Compute nodes are interconnected using a control and management node which split, distribute and mange processing. Compute nodes can be added or remove by adding or removing servers to the rack.
MPP Architecture
Advantages:
- Relatively inexpensive hardware needed to scale (cost of new server is cheaper than buying a new machine)
- No resource contention across compute nodes
- Scaling up or down is easy and can be performed without taking down the system
- Ability to add failover and backup servers
- Efficiently/Quickly process large data volumes
- No limitation on the number of compute nodes that can be added
Disadvantages:
- Additional maintenance required (rack space, cooling, monitoring)
- Additional maintenance costs (power, cooling, hardware upgrades)
- Unused resources during small and medium data volumes
As mentioned earlier, traditional BI, Data Warehouse and DBMS tools are not able to keep up with the volumes of data. Moore's law is unable to keep up with velocity and volume of data growth. Shared resources and memory prevent scalability and distributed processing. These tools use a Symmetric Multi-Processing (SMP) architecture.
In order to accommodate for the hardware lag (disparity between Moor's Law and data growth), integration/coupling of hardware needs to be utilized. Massively Parallel Processing (MPP) architecture allows for the combination of hardware resources to be pooled to create a more powerful system that is able to meet the demands of processing and storing Big Data while still providing usability of tools using the SMP architecture.
 RSS Feed
RSS Feed

{kind=link}
{kind=link}